Research
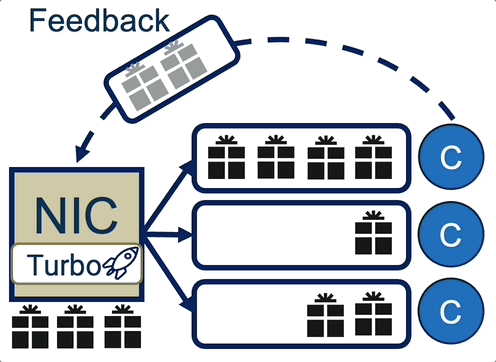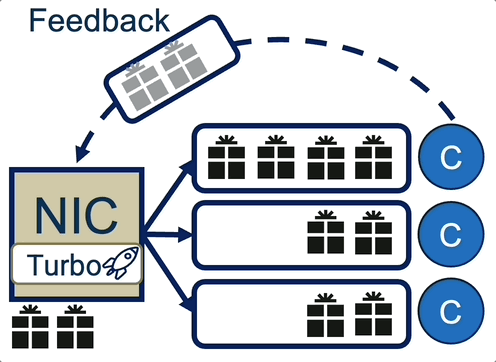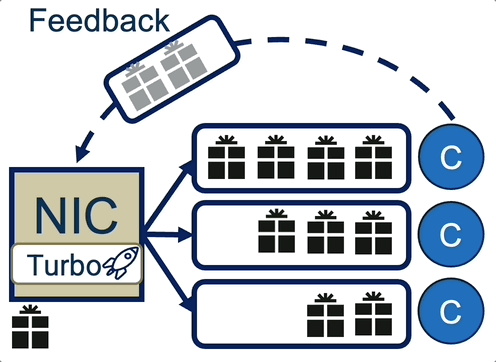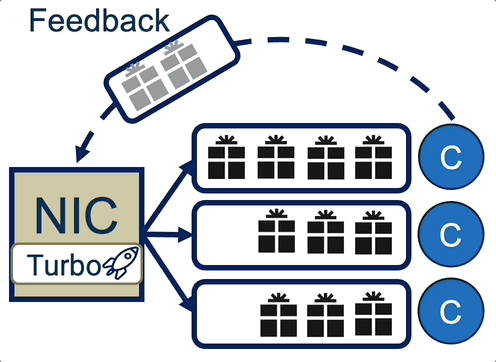
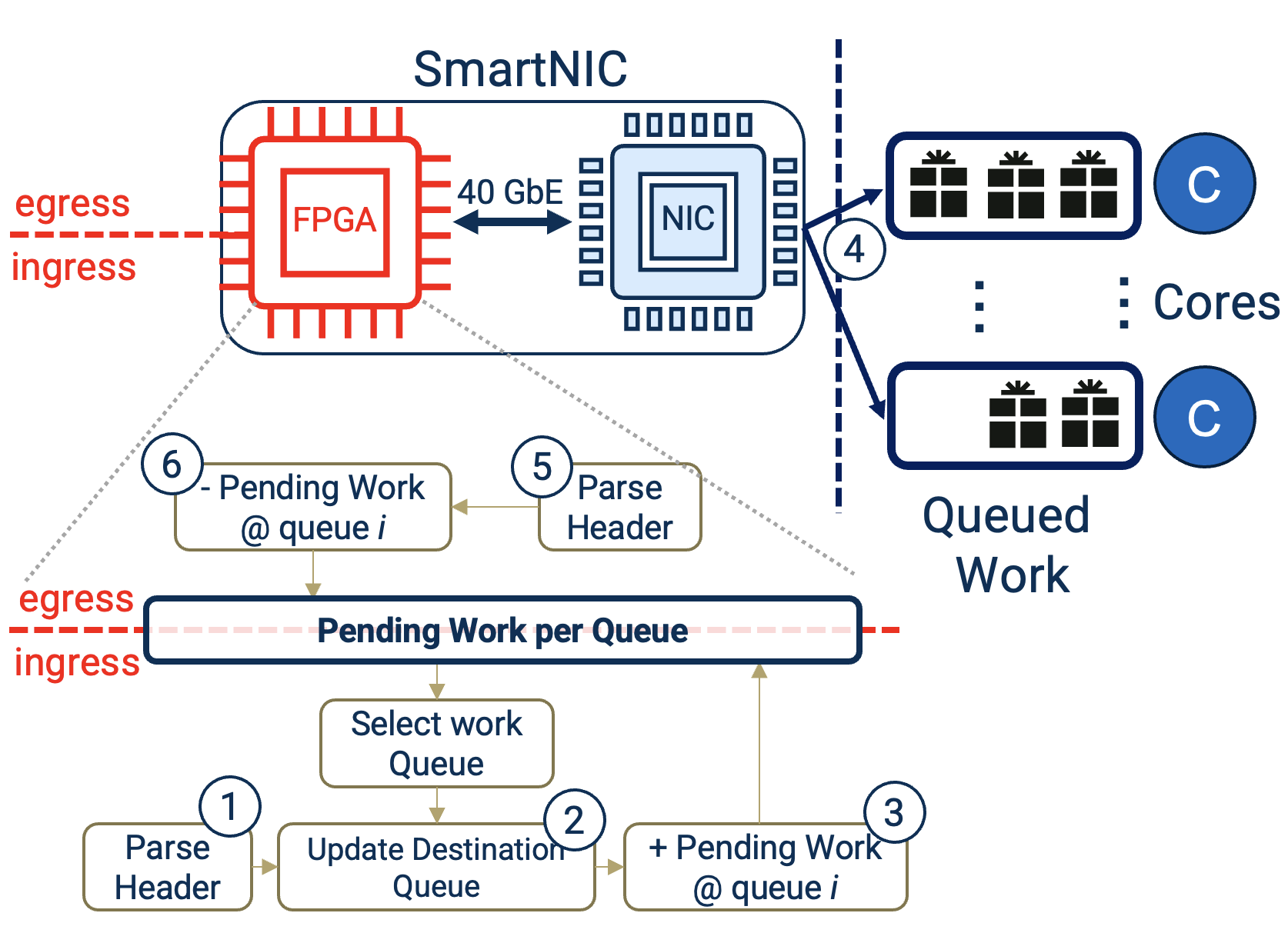
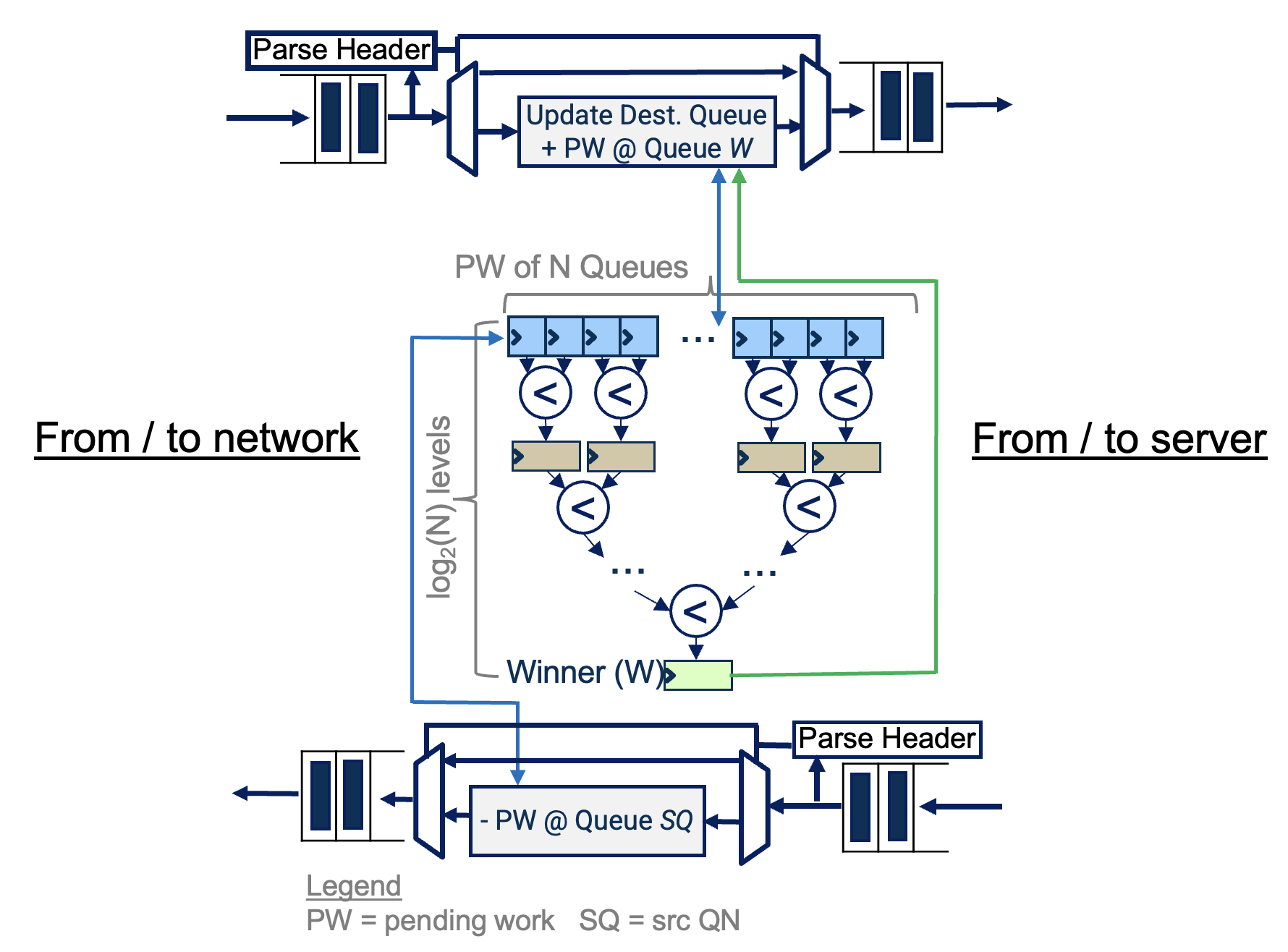
Turbo: SmartNIC-enabled Dynamic Load Balancing of µs-scale RPCs (published in HPCA’23)
Insight: μs-scale RPCs require immediate load imbalance detection and remediation mechanism operating on a per-packet granularity. Existing NIC-based mechanisms (RSS, RSS++) are static and too coarse grained and software-based mechanisms introduce significant overhead for µs-scale RPCs.
Turbo’s load balancing intelligently steers packets into user space queues at line rate using its two adative policies (i.e., JSQ —Join Shortest Queue— and JLQ —Join Lightest Queue-), improving throughput under tight tail latency SLOs and reducing tail response latency.
Turbo was implemented on a Mellanox Innova Flex-4 FPGA SmartNIC and evaluated on an RDMA UD microbenchmark and Masstree-RDMA key-value store with various service time distributions.
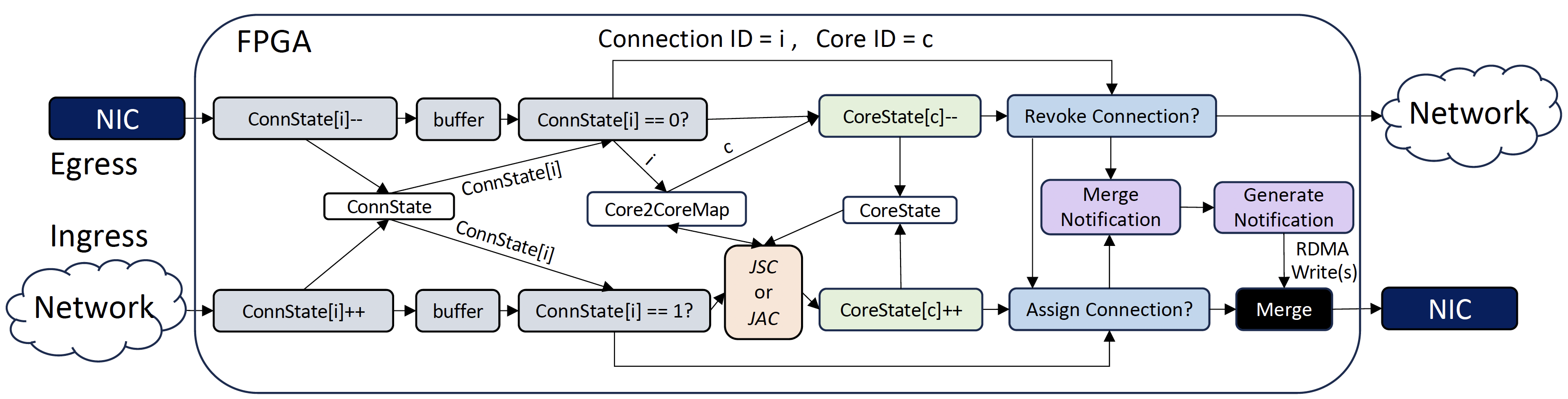
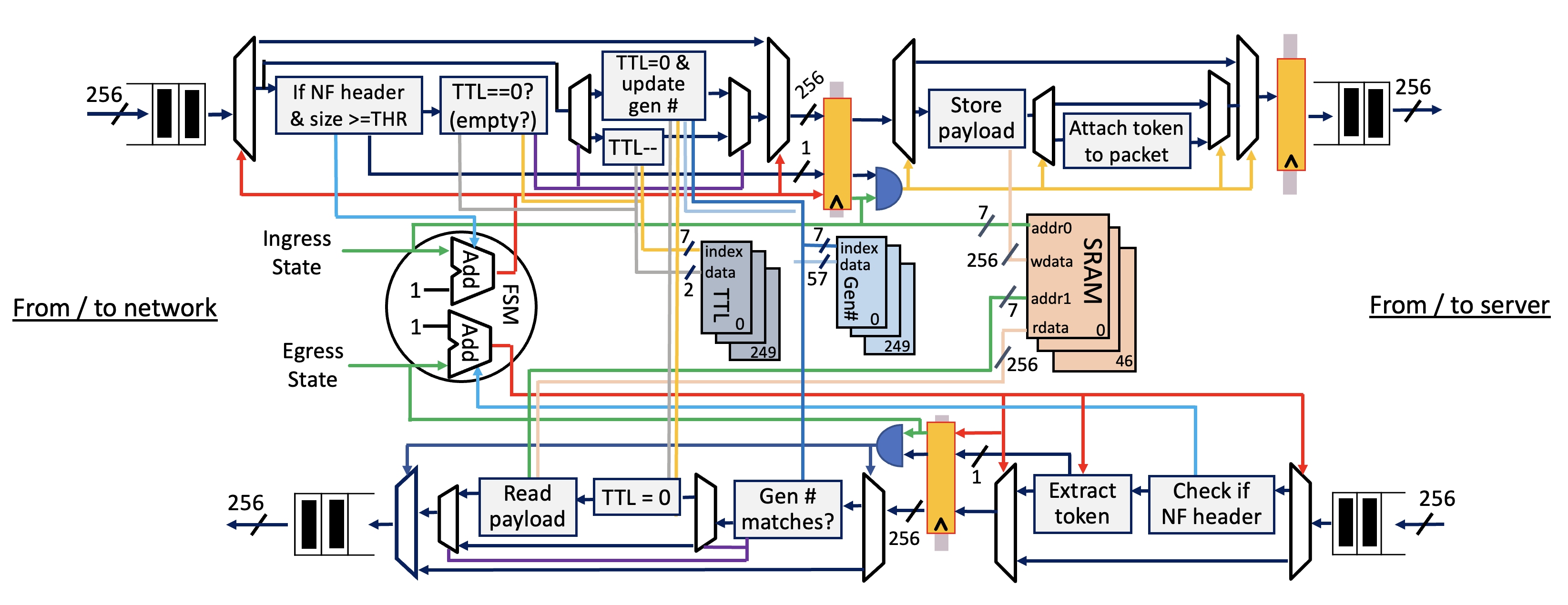
NFSlicer: Data movement optimization for shallow network functions (on ArXiv)
Insight: Moving packets across PCIe increases contention on the PCIe interface, increasing PCIe interface latency. Shallow network functions can benefit from the reduced data movement, as they only require the packet header for processing.
NFSlicer realizes a NIC-based mechanism to slice packets into header and payload on ingress, sending only the header to the host, storing payload on the NIC. The payload is then spliced back to the header on egress.
NFSlicer’s slice/splice mechanism was designed in Vivado HLS and synthesized using the Synopsys Design Compiler on an open-source 15nm technology node library to extract power, area, and timing estimates and ensure line rate performance,
Enabling payload slicing eliminates data movement bottlenecks between the NIC and server, reducing tail response latency.
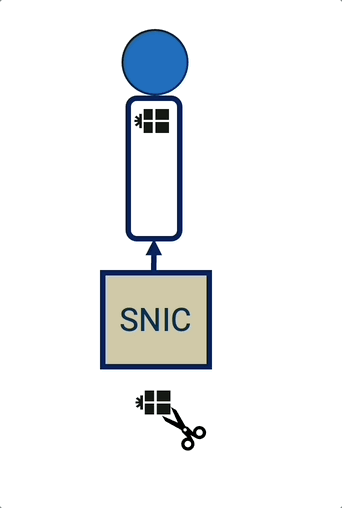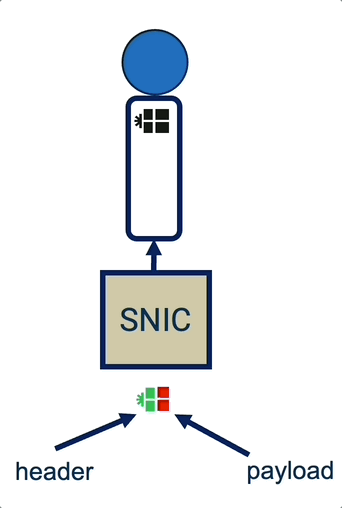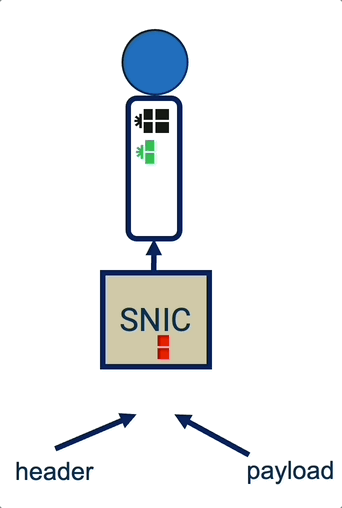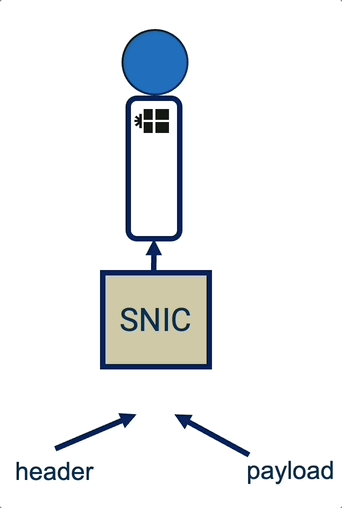
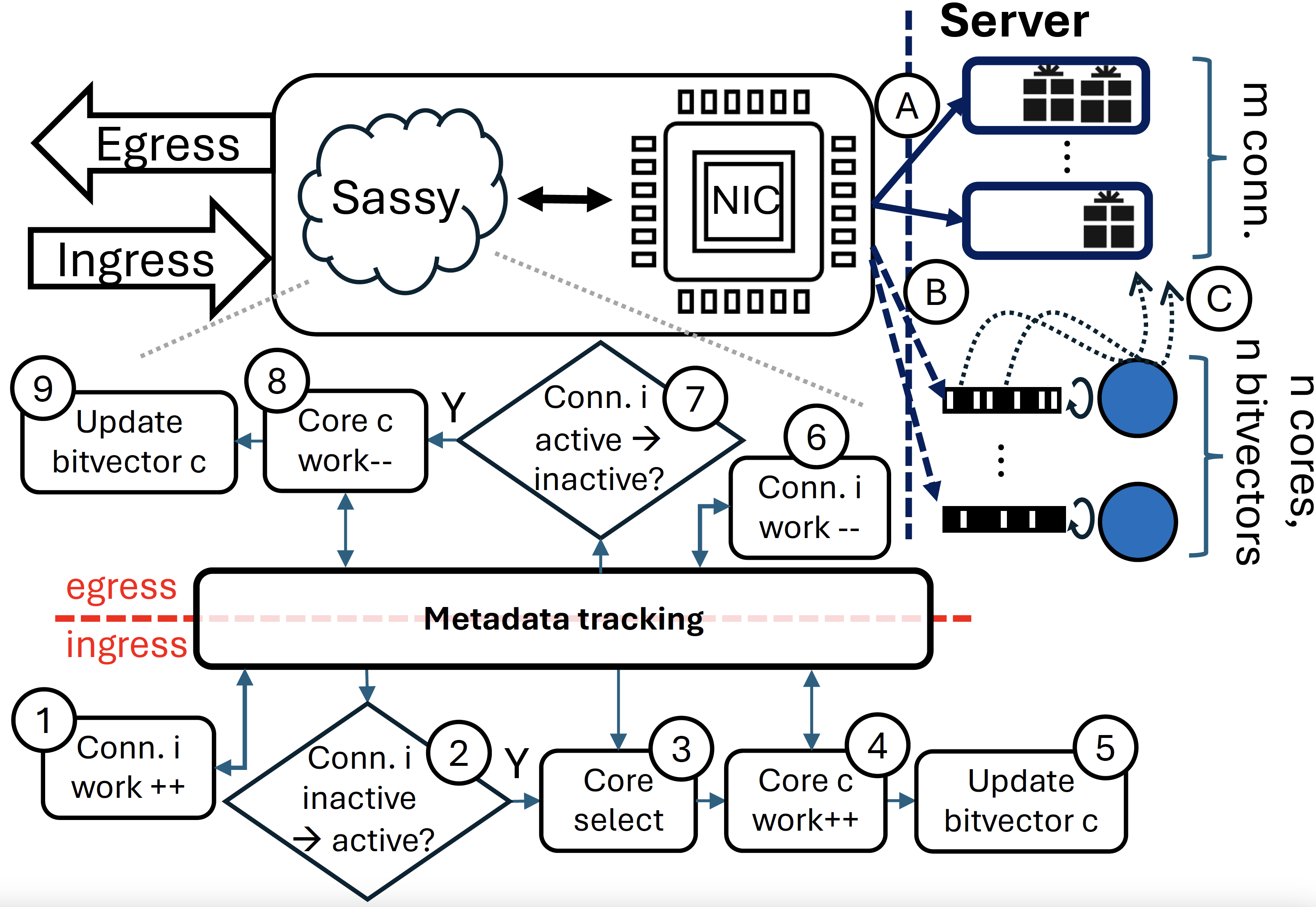
Sassy: SmartNIC-Assisted Notification Delivery for μs-scale RDMA Workloads (published in HPCA’26)
Insight: RDMA’s polling-based arrival notification approach poses a performance challenge at high core and connection counts. RDMA’s offered mechanisms present a triangle tradeoff between wasteful idle polling, high inter-core synchronization costs, or inter-core load imbalance—all of which drastically hurt the peak attainable throughput for latency-sensitive services with μs-scale service times.
Sassy is a smartNIC-based notification mechanism that breaks this tradeoff, optimizing the performance and scalability of servicing μs-scale RPCs over high connection counts. Sassy eliminates performance overheads stemming from idle polling and inter-core synchronization, while balancing the load of active RDMA connections across available cores.
Sassy was implemented on an FPGA smartNIC and evaluated on an RDMA RC microbenchmark as well as a high-performance key-value store with a range of traffic patterns.
Full paper coming soon!